《Data Warehouse Toolkit》:第一章,数仓、商业智能与维度建模入门
第一章,探讨了维度建模的核心概念以及介绍了Kimball DW/BI架构的主要组件。
数仓和商业智能的目标
维度建模简介
维度建模作为呈现分析数据的首选技术手段已经被广泛接受,因为它解决了两个同时性的需求:
- 交付的数据是业务人员是可以理解的;
- 交付快速查询的能力;
尽管维度建模通常实现在关系型数据管理系统中,但是它不同于第三范式,3NF寻求的是消除数据冗余。3NF和维度模型都能够用ERDs来表示,因为它们都是由连接后的关系表组成的;它们之间关键性的区别是规范化的程度。
标准的3NF结构在业务处理当中是极其有用的,因为更新或插入的事务只能在一处对数据库进行操作。然而,标准化的模型对于BI查询太过复杂了。
注意:维度模型包含了与标准化模型一样的信息,但维度模型是以一种用户易理解、查询高效、以及能应对变化的格式对数据进行打包。
星形模型和OLAP立方体
在关系型数据库管理系统中实现的维度模型被称为星形模型,在多维数据库环境中实现的维度模型被称为联机分析处理(OLAP)立方体。

用于测度的事实表
维度模型中的事实表用于存储由组织内的业务过程中事件所产生的表现测度(performance measurement)结果。应该努力做到将这些由业务过程产生的低层级测度数据存到一个维度模型中。因为测度数据大多数都是最大的数据集,不应该为了解决企业内多部门的功能被复制到多处。
术语事实(fact)代表的是一种业务衡量标准。想象一下,站在市场的角度来观察商品被出售,在每次交易事务的时候写下每种商品的单位数量和销售额。这些测度随着商品在收银机处被扫描后就被捕获了。
事实表中的每一行对应一个测度事件。每行中的数据所处于特定的明细级别,被称为粒度。例如,交易事务中,每次商品被出售都会有一行数据。维度建模的一个核心思想是一个事实表中所有测度数据行必须是同样的粒度。
注意:物理世界中的一个测度事件会一对一地对应事实表中一行,这是维度建模的基本原则。
最有用的事实是数值的和可加的。关于事实表中数值型事实的分类介绍,可以参考Kimball Group的《Additive, Semi-Additive, and Non-Additive Facts》。
事实通常为连续值,这有助于区分事实和维度属性。文本型的事实理论上是存在的,但是很少会使用到。大多数情况,文本类型的测度都是某事物的描述。设计者应该尽量将文本数据放到维度中,在那里这些文本可以与其它文本型的维度属性更有效地联系起来,并且占用更少的空间。不要在事实表中存储冗余的文本信息。除非文本在事实表中对于每行都是唯一的,否则它们是应该被放在维度表中。
事实表常常是在行数上是深的,但在列数上窄的。
所有事实表都有两个或更多个外键,它们连接维度表的主键。当事实表中的所有键都各自正确匹配上它们在相应维度表中的主键时,这些表满足了参照完整性。
事实表表达的是多对多的关系。其它的就是维度表。
用于描述上下文的维度表
维度表是作为事实表的完整性相伴的。维度表包含着与之关联的业务流程测度事件的文本性上下文。它们描述的是与事件所相关的“谁(who)、做了什么(what)、在哪里(where)、什么时候(when)、如何做的(how)、以及为什么做的(why)”。
维度表通常都会有很多列或者属性,会有比事实表更少的行。维度属性提供了查询约束、分组、以及报表标签的主要来源。
属性应该由真词组成,而不是模糊的缩写。你应该尽量最少地在维度表中使用码值,而是使用更详尽的文本属性。
在很多方面,数仓实际上就是维度属性;DW/BI环境的分析能力与维度属性的质量和深度是成正比的。花费在提供详尽业务术语的时间越多,越好。花费在增添一个属性列上域值的时间越多,越好。花费在确保一个属性列上值的质量的时间越多,越好。
在对操作源数据进行分类的时候,有时一个数值型数据元素是事实还是维度属性有时是不明确的。通常,问一下该列是否具有很多值、并参与计算(这样的列是事实)或者是基本上稳定、参与约束和行标签的离散值描述(这样的列是纬度属性)就可以做出判断了。偶尔,你不能确定如何区分的时候,可以将该数据元素建模为任何一种形式(或者两种形式)。
注意:一个数值型的量是事实还是维度属性不是一件特别难的决定。连续型数值差不多都是事实,小范围的离散型数值几乎都是维度属性。
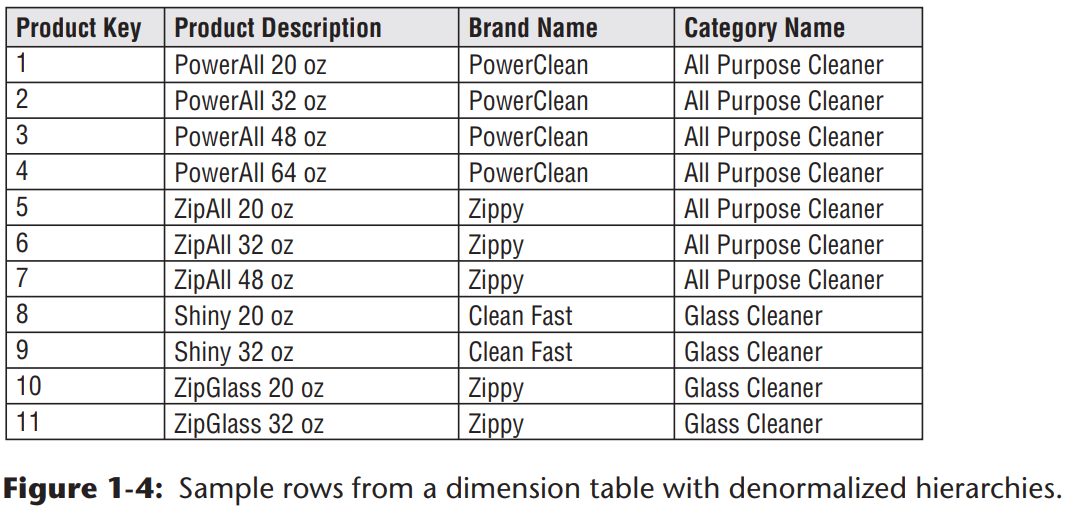
图1-4所显示的维度表表示了层级关系。例如,从产品上卷到品牌,然后再上卷到到类别。对与产品维度中的每一行,你应该存储相关联的品牌和类别的描述。基于易用和查询性能的层级描述信息在存储冗余的。不要急于通过在产品维度中只存储品牌的码值、创建单独的品牌查找表,同样对于类别描述也做成单独的类别查找表来规范化数据。这样的规范化称为雪片化。非3范式,维度表通常都是高度非规范化的,每个维度表中都是一个扁平的多对一的关系。因为维度表通常是几何级数的小于事实表,通过规范化或雪片化来提升存储效率实际上对于整体数据库的规模没有实质的影响。
星形模型中连接事实表和维度表
每个业务过程都表示为维度模型。

关于维度模型首先要注意到的是它的简单和对称。
Kimball的DW/BI架构

业务源头系统
源系统的最优先的是处理工作和可用性。对于源系统的业务查询是很有限的。
抽取、转换和加载系统
抽取是将数据获取到数仓环境中的第一步。抽取意味着读取并理解源数据,并将所需要的数据复制到ETL系统。
在数据被抽取到ETL系统之后,会有很多潜在的转换,例如清洗数据(校正拼写错误、解决域冲突、处理缺失元素、以及解析到标准格式)、合并来自多个源的数据、以及对数据去重。
ETL过程的最后一步是构建并将数据加载到呈现层中的目标维度模型。因为在交付时,ETL系统的主要任务是交付维度表和事实表,所以这些子系统是至关重要的。所定义的这些子系统很多都主要集中在维度表的处理上,例如代理键的分配、查找码值来提供合适的描述、拆分或联合列来呈现合适的数据值、或者将底层的3范式表结构连接成扁平的非范式维度。相反,事实表通常都会很大、加载很耗时,但是将它们准备给呈现层通常都是很直接的。
关于ETL系统中的数据是否应该在加载给呈现层的维度结构以前应该被重物理化为规范化结构,这一点仍是行业的痛点。ETL系统通常都是。很多时候,ETL系统不是基于关系技术的,可能只是依赖平面文件的系统。在校验完数据后,再构建3NF的物理数据库有时是没有意思的,。
呈现层为了支撑商业智能
DW/BI的呈现层是数据被组织、存储、以及可直接用于用户、报表编写人员、以及其它分析类的BI应用程序的查询的地方。因为幕后ETL系统是禁入的,所以呈现层就成为了DW/BI环境,它是业务通过访问工具和BI应用程序能看到和触及的全部。
对于呈现层我们有几个强烈的观点。首先,我们强调维度模型中的数据要被呈现、存储、以及访问。第二,呈现层必须包含明细的、原子性数据。最细粒度的数据必须在呈现层是可用,这样用户就可以询问最准确的问题了。第三,呈现数据层应该是围绕业务流程测度事件进行的结构化,而不应该是为了交付一天的报表而进行的设计。一个企业的业务流程是跨组织部门和功能边界的。应该是为原子性销售度量构建单个事实表,而不是为不同部门制定不同的策略。
注意,DW/BI系统的呈现层中的数据必须是维度的、原子的、以业务流程为中心的、依托企业数仓bus架构的。数据一定不是根据某个单独部门的理解被构建出来的。
商业智能应用程序
用餐馆来比喻Kimball架构
幕后厨房中的ETL
ETL系统类比于餐馆中的厨房。有才能的厨师选用原始材料,把它们转换成用餐者所享用的美食。
厨房要达到组织有序,需要考虑几个设计目标。第一,布局必须是高效的。第二,厨房交付始终如一的质量。第三,厨房输出的菜肴必须是高度完整的。
数仓中的ETL系统类似于餐馆中的厨房。源数据被神奇般地转换为有意义的、可展示用的信息。在任何数据从源被抽取之前,幕后ETL系统必须被布局和架构好。就像厨房,ETL系统被设计以确保吞吐量。它必须高效地将原始源数据转换到目标模型,最小化不必要的移动。
显然,ETL系统也极度关心数据质量、完整、和一致。输入数据在进入的时候按照合理的质量被检查。
注意,一个被正确设计的DW/BI环境会权衡台前BI应用程序的工作以利于幕后ETL系统的工作。台前的工作必须有业务人员反复再三来完成,然而幕后工作由ETL人员一次性完成。
前端餐厅中的数据呈现和BI
餐馆通过基于四个不同的质量被打分:
- 食物(质量、味道、卖相)
- 装饰(吸引人、舒适的环境)
- 服务(及时配餐、贴心的后勤人员、以及按顺序配送食物)
- 费用