Druid Quick Start
本篇是一篇Druid的Quick Start,本篇不同于Druid官网的Quick Start,思路借鉴了Druid官网的注册规范一文,本篇更注重从任务、数据两者因果关系上进行介绍。
准备工作
启动druid
1 | ./bin/start-micro-quickstart |
[Fri Nov 20 21:41:44 2020] Running command[zk], logging to[/Users/dream/Env/druid/apache-druid-0.20.0/var/sv/zk.log]: bin/run-zk conf
[Fri Nov 20 21:41:44 2020] Running command[coordinator-overlord], logging to[/Users/dream/Env/druid/apache-druid-0.20.0/var/sv/coordinator-overlord.log]: bin/run-druid coordinator-overlord conf/druid/single-server/micro-quickstart
[Fri Nov 20 21:41:44 2020] Running command[broker], logging to[/Users/dream/Env/druid/apache-druid-0.20.0/var/sv/broker.log]: bin/run-druid broker conf/druid/single-server/micro-quickstart
[Fri Nov 20 21:41:44 2020] Running command[router], logging to[/Users/dream/Env/druid/apache-druid-0.20.0/var/sv/router.log]: bin/run-druid router conf/druid/single-server/micro-quickstart
[Fri Nov 20 21:41:44 2020] Running command[historical], logging to[/Users/dream/Env/druid/apache-druid-0.20.0/var/sv/historical.log]: bin/run-druid historical conf/druid/single-server/micro-quickstart
[Fri Nov 20 21:41:44 2020] Running command[middleManager], logging to[/Users/dream/Env/druid/apache-druid-0.20.0/var/sv/middleManager.log]: bin/run-druid middleManager conf/druid/single-server/micro-quickstart
各个服务会将日写入var/sv目录:
var/sv/
├── broker.log
├── coordinator-overlord.log
├── historical.log
├── middleManager.log
├── router.log
└── zk.log
准备数据
将以下内容写入文件:quickstart/me-tutorial-data.json
1 | {"ts":"2018-01-01T01:01:35Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2", "srcPort":2000, "dstPort":3000, "protocol": 6, "packets":10, "bytes":1000, "cost": 1.4} |
准备索引描述
将以下内容写入文件:quickstart/me-tutorial-index.json
1 | { |
提交任务
1 | bin/post-index-task --file quickstart/me-tutorial-index.json --url http://localhost:8081 |
Beginning indexing data for me-tutorial
Task started: index_parallel_me-tutorial_kkcdjied_2020-11-20T13:44:12.560Z
Task log: http://localhost:8081/druid/indexer/v1/task/index_parallel_me-tutorial_kkcdjied_2020-11-20T13:44:12.560Z/log
Task status: http://localhost:8081/druid/indexer/v1/task/index_parallel_me-tutorial_kkcdjied_2020-11-20T13:44:12.560Z/status
Task index_parallel_me-tutorial_kkcdjied_2020-11-20T13:44:12.560Z still running…
Task index_parallel_me-tutorial_kkcdjied_2020-11-20T13:44:12.560Z still running…
Task index_parallel_me-tutorial_kkcdjied_2020-11-20T13:44:12.560Z still running…
Task index_parallel_me-tutorial_kkcdjied_2020-11-20T13:44:12.560Z still running…
Task index_parallel_me-tutorial_kkcdjied_2020-11-20T13:44:12.560Z still running…
Task finished with status: SUCCESS
Completed indexing data for me-tutorial. Now loading indexed data onto the cluster…
me-tutorial loading complete! You may now query your data
探索
我们看Segments页面,列出了3个分片,如下:

我们在粒度说明中,开启了rollup,且queryGranularity为分钟,如下:
1 | "granularitySpec" : { |
这样我们原始的摄入数据(未标注黄色背景的行)就会被索引任务按分钟粒度,执行“上卷”操作,“上卷”结果如下图中黄色背景标注的行。并且,我们定义了"intervals" : ["2018-01-01/2018-01-02"],所以03小时的两条记录将直接被任务所忽略掉:

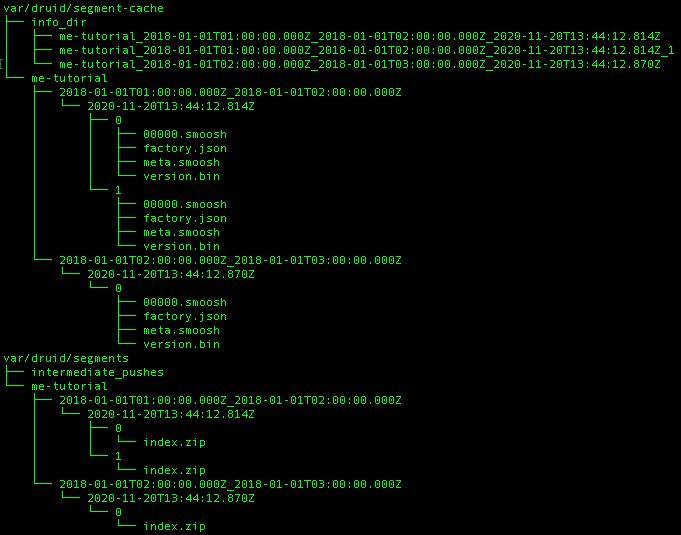
粒度说明中,segmentGranularity为小时,即数据按小时进行分片,最终,2018-01-01 01小时“上卷”后的记录有6条,02小时有2条;因为我们定义了maxRowsPerSegment为5,所以01小时的数据被划分到了两个数据分片。数据最终的逻辑划分如下图所示:

我们看一下磁盘中数据文件的情况: